DevLog : J'ai enfin mis mon portfolio en ligne et voici comment






Je vais vous raconter comment j'ai codé ce portfolio de A à Z (sans vibe coder). Je vous partage mon choix de technos, mes galères en cours de route et surtout mes astuces pour tout auto-héberger sans exploser le budget. Installez-vous, on plonge dans les coulisses de mon setup de solopreneur.
INTRODUCTION
Depuis longtemps, je rêvais d’un portfolio à la hauteur de mes ambitions. Pendant un temps, mes compétences se limitaient à télécharger un template HTML + Bootstrap, copier-coller le code dans des composants Vue.js, et l’héberger gratuitement sur Vercel avec un sousdomaine .vercel.app.
À ce stade, ce n’était rien de plus qu’un CV en ligne un peu plus fourni. Chaque fois que je voulais ajouter un nouveau projet, il fallait modifier le code manuellement. Quant au formulaire de contact présent dans le template… impossible de le faire fonctionner : je n’avais aucune notion de backend ni de base de données. Le portfolio est donc resté figé comme ça pendant des mois.
Fin octobre 2025, après plusieurs projets académiques inachevés, j’ai pris une décision radicale : je terminerais ce portfolio coûte que coûte, sans me lancer dans aucun autre projet tant qu’il ne serait pas en ligne, accessible depuis internet, et équipé d’un vrai nom de domaine professionnel.
C’était une résolution difficile, mais nécessaire. Ce que je n’avais pas anticipé, c’est que ce « petit » projet me prendrait plus de six mois et m’apprendrait bien plus que tous mes projets précédents réunis. Surtout, j’ai découvert l’écart abyssal qui existe entre un projet « presque fini » en local et un site prêt pour la production. Dans ce devlog, je te raconte tout : les objectifs que je m’étais fixés, les technologies et outils que j’ai utilisés et pourquoi, comment ça s’est passé d’octobre 2025 à avril 2026 avec toutes les galères auxquels j’ai dû faire face et les pistes que j’ai abandonnées.
I. MES OBJECTIFS
Mon but était surtout de montrer mes compétences et m’entraîner sérieusement. J’en avais marre de laisser tous mes projets inachevés. Cette fois, je me suis dit que j’allais aller jusqu’au bout, faire un vrai chantier où je fais tout moi-même. Et j’avais avec sa des sous objectifs comme par exemple :
A. Self Hoster
Héberger une API Laravel, ce n’est pas du tout la même chose qu’héberger un simple site statique sur Vercel. Quand Laravel Cloud est sorti, j’ai sauté dessus direct. La promesse était trop belle : héberger mes projets backend aussi facilement qu’un site statique, avec gestion automatique de la base de données, des files d’attente, de Redis, du stockage S3, et même bientôt des WebSockets avec Laravel Reverb.
Le réveil a été brutal.
J’ai testé leur offre « Pay as you go » pendant un mois. J’ai déployé une petite application Laravel avec une base MySQL, juste pour voir. Aucun trafic, aucune queue, rien. À la fin du mois, j’ai reçu une facture de 7 dollars (environ 4000 FCFA). Pour moi, c’était exorbitant. Le cloud, c’est vraiment un truc de nantis.
Cette expérience m’a fait prendre conscience très vite que si j’ajoutais les files d’attente, Redis, le stockage S3 et du vrai trafic, la facture allait exploser avec des coûts imprévisibles. Du coup, j’ai pris la décision de passer sur un VPS pour avoir des coûts fixes, sans surprise, et bien moins chers (autour de 4 dollars par mois).
En résumé, cette petite facture m’a convaincu qu’il était obligatoire pour moi d’apprendre à auto-héberger mes projets. D’ailleurs, j’ai découvert plus tard qu’on peut avoir beaucoup des avantages du cloud (une belle interface de gestion, etc.) grâce à des solutions open source… mais ça, c’est une autre histoire que je raconterai plus tard.
B. Le respect des standards de programmation
Je voulais une application propre, qui respecte les standards de programmation, mais sans tomber dans le fanatisme des architectures ultra-complexes qu’on voit sur Twitter. Pas question de suivre aveuglément les gourous. Je voulais du code propre, sans répétitions inutiles, mais sans non plus faire une classe pour chaque petite méthode comme certains le prônent.
Concrètement, ça voulait dire :
Éviter le copier-coller : si un bout de code est utilisé plusieurs fois, je le mets dans une méthode réutilisable.
Avoir un format de réponse JSON cohérent pour toutes les routes.
Bien paginer les listes.
Côté sécurité, j’avais aussi quelques objectifs clairs :
Vérifier les emails à l’inscription pour éviter les faux comptes avec des adresses qui n’existent pas.
Implémenter la fonctionnalité « mot de passe oublié » (dans mes anciens projets, perdre son mot de passe signifiait souvent perdre son compte).
Et surtout, passer à une authentification par session avec l’identifiant stocké dans un cookie HTTP-only. Ça protège beaucoup mieux contre les attaques XSS, car le JavaScript ne peut pas accéder au cookie et voler le jeton. Contrairement aux tokens Sanctum que j’utilisais avant et que je stockais dans le localStorage, où n’importe quel script malveillant pouvait les intercepter.
Mais le plus gros changement concerne l’API elle-même.
En tant qu’autodidacte, je pensais vraiment que renvoyer des grosses réponses JSON imbriquées était le consensus général. Tous les tutoriels que je voyais faisaient comme ça : quand tu demandes un article, tu reçois l’article + ses tags + ses commentaires + le nombre de likes, etc. Je croyais sincèrement que c’était la bonne façon de faire.
J’ai découvert que ce n’était pas forcément la meilleure approche.
Ma nouvelle philosophie (que je vais garder pour mes prochains projets) est beaucoup plus simple et granulaire :
Quand on demande /api/posts/1, je renvoie uniquement les informations de base de l’article.
Tu veux les tags ? → /api/posts/1/tags
Tu veux les stats (nombre de likes, partages, commentaires) ? → /api/posts/1/stats
Tu veux tous les commentaires ? → /api/posts/1/comments
Les inconvénients : Le client doit faire plusieurs requêtes fetch pour afficher une page complète. C’est un peu plus de travail côté front.
Les avantages :
L’API est plus simple à développer : je n’ai plus à me demander « est-ce que je dois charger tous les relations ou pas ? » et je n’ai plus de problèmes d’eager loading compliqués.
Ça résout naturellement l’under-fetching et l’over-fetching sans utiliser graphql.
C’est beaucoup plus facile à mettre en cache, que ce soit côté front (avec TanStack Query par exemple) ou côté back (avec Redis). Exemple concret : si je change juste le nom d’un tag, je n’ai pas besoin d’invalider le cache de tous les articles qui utilisaient ce tag. Je supprime uniquement le cache de la route /api/posts/1/tags. C’est beaucoup plus précis et performant sur le long terme.
En résumé, je voulais respecter l’esprit de REST (et un peu HATEOAS), mais à ma façon : pas de grosses réponses imbriquées, mais des réponses JSON granulaires et indépendantes. Je ne suis pas allé jusqu’à mettre des liens hypermédia partout, mais l’idée de ressources séparées et modulaires est là.
C. Les performances
La performance a été une vraie obsession pendant tout le projet.
Tout est parti du stigmate classique : « Tu fais du Laravel donc du PHP… et PHP c’est lent ». Au début, j’y croyais dur comme fer. Cette impression était renforcée par le fait qu’en local, sur mon vieux PC sous Windows, mes requêtes mettaient parfois plusieurs secondes à répondre avant de s’afficher sur le front. Ça me stressait énormément.
Puis j’ai fini par comprendre que le vrai problème venait surtout de ma machine et de mon OS. Quand je suis passé sur Ubuntu, tout est devenu beaucoup plus rapide. Le langage n’était pas le coupable principal.
En plus, Laravel était le framework que je maîtrisais le mieux. Changer pour autre chose au milieu du projet n’était pas une option réaliste. Du coup, cette pression m’a poussé à faire plusieurs choses un peu extrêmes :
J’ai d’abord essayé de faire un site entièrement statique qui se régénérait à chaque nouvel article pour avoir un maximum de performance. Je vous en parlerai plus en détail dans la partie « Les trucs que j’ai abandonnés ».
Ensuite, à cause de cette quête de performance, j’ai même envisagé d’apprendre Rust + Actix. Heureusement que je ne suis pas allé au bout : si j’avais pris cette route, le portfolio n’aurait pas pris 6 mois… mais plutôt 2 ans. Et aujourd’hui je ne maîtrise toujours pas Rust.
Finalement, je suis resté sur Laravel. Même si sur internet beaucoup de gens disent des phrases du style « Comment les gens osent encore utiliser PHP en production ? C’est tellement lent », la réalité est tout autre. La majorité du web tourne encore avec PHP sans problème. Personnellement, j’utilise plein de sites PHP au quotidien et ils sont loin d’être lents.
Du coup, pour calmer un peu ma psychose de la performance, je me suis rabattu sur Laravel Octane avec FrankenPHP. Ça m’a permis d’avoir un bon gain de vitesse. Mais honnêtement, le serveur PHP natif aurait largement suffi. C’était plus une psychose personnelle qu’un vrai besoin technique.
D. Les fonctionnalites
Je ne voulais pas d’un simple CV en ligne figé. Je voulais une vraie plateforme vivante, avec des fonctionnalités qui sortent un peu de l’ordinaire pour un portfolio.
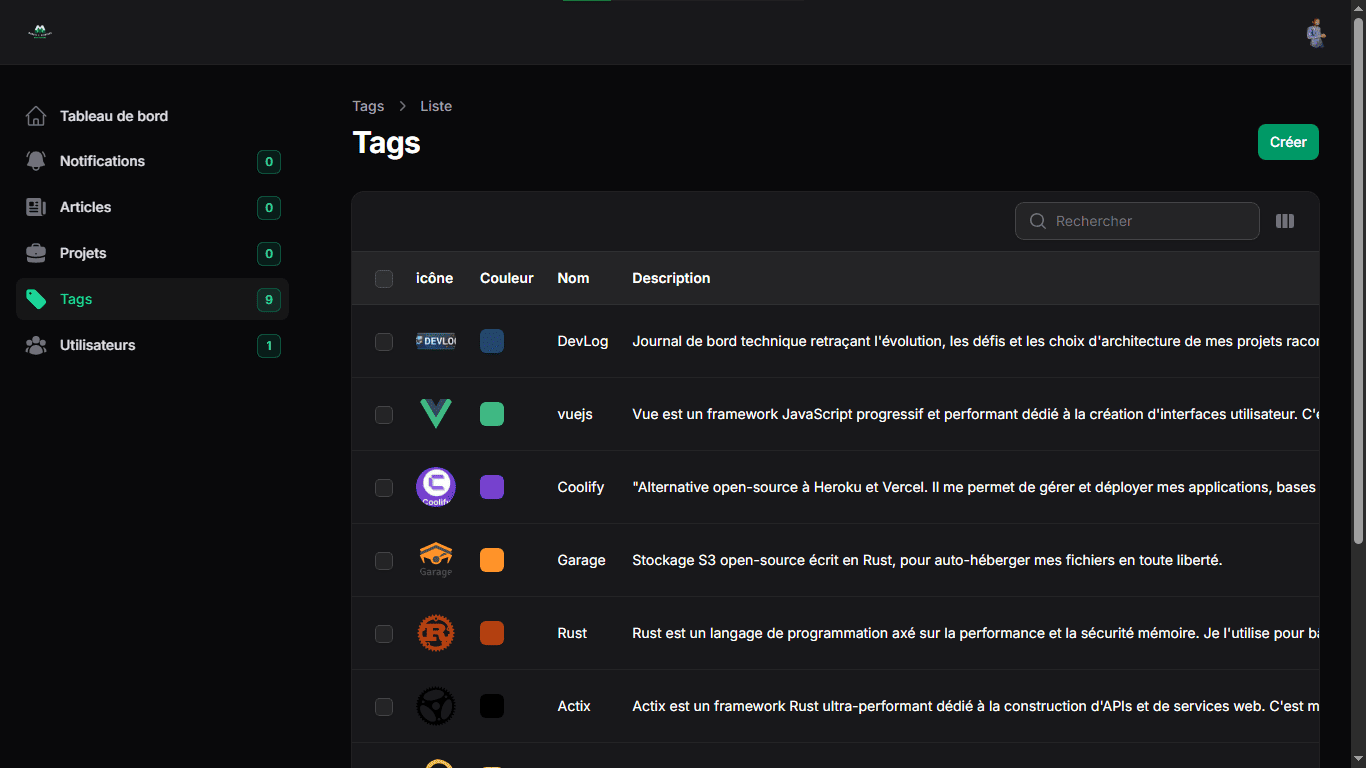
Du côté administration, j’ai fait un dashboard complet qui me permet de gérer facilement tout le contenu du site :
Créer et modifier les articles (le contenu est du HTML sauvegardé directement en base de données et affiché tel quel côté frontend)
Gérer les projets avec leurs tags et leurs images respectives
Une gestion simple des utilisateurs (pouvoir les bannir ou débannir)
Une section pour voir toutes les notifications : messages envoyés via le formulaire de contact et nouveaux commentaires sur les articles
Côté visiteurs, j’ai voulu rendre l’expérience beaucoup plus interactive. J’ai implémenté l’authentification OAuth avec Google et GitHub pour que les gens puissent se connecter très facilement, sans avoir à créer un compte manuel.
Pourquoi tout ça ? Parce que je voulais reproduire un peu les fonctionnalités des réseaux sociaux que j’avais déjà essayées dans mes anciens projets : liker, commenter et partager.
Je suis allé assez loin sur ces points :
Un système de like/unlike intelligent : on ne peut pas liker plusieurs fois le même élément. Si on reclique, ça delike.
Un système de commentaires avec réponses imbriquées à profondeur infinie (alors que la plupart des sites limitent à un seul niveau de réponses). La récursivité m’a bien fait galérer surtout lors de l’affichage cote front, mais j’y tenais.
Et surtout, la possibilité d’uploader des fichiers directement dans les commentaires ou dans le formulaire de contact. C’est un truc que je vois très rarement sur les portfolios, et c’est un peu là que j’ai essayé d’innover.
En gros, je voulais que les visiteurs puissent interagir avec mon travail comme sur un vrai réseau social, sans avoir à remplir un formulaire avec leur nom à chaque commentaire. Je voulais quelque chose de fluide et naturel, auquel tout le monde est déjà habitué grâce aux réseaux sociaux.
II. LES TECHNOLOGIES UTILISEES
Pour ce portfolio, je voulais un stack que je maîtrisais déjà en grande partie, tout en ajoutant les outils nécessaires pour atteindre mes objectifs (self-hosting, performance, administration facile, etc.). Je ne suis pas parti dans des technologies trop exotiques, mais j’ai quand même appris pas mal de nouvelles choses.
Voici le détail de ce que j’ai utilisé et surtout pourquoi.
A. Backend
Comme vous l’avez sûrement deviné, j’ai utilisé Laravel, le framework PHP des artisans du web. J’aime son architecture MVC, sa simplicité d’utilisation, et surtout son écosystème très riche. Quand tu rencontres un problème, il y a presque toujours une solution ou un package existant. Ça m’a beaucoup aidé pendant le développement.
En local, j’ai utilisé Laravel Sail pour le développement. C’est un outil en ligne de commande qui génère automatiquement un fichier docker-compose.yml prêt à l’emploi. Pendant l’installation, tu peux choisir les services dont tu as besoin. J’ai ajouté une base de données, un serveur SMTP pour les mails, et Redis. Super pratique pour démarrer sans se prendre la tête avec Docker au début.
Pour l’interface d’administration, j’ai utilisé Filament. C’est un framework d’interface admin ultra-complet pour Laravel. À partir des migrations, il génère automatiquement les CRUD (liste, formulaire de création/modification), des dashboards avec stats, etc.
Ce qui m’a vraiment convaincu, c’est son Rich Editor (basé sur Tiptap). Je pouvais rédiger mes articles en HTML riche directement dans l’admin, et le contenu est sauvegardé tel quel en base de données pour être affiché côté frontend. J’aurais pu coder mon propre dashboard, mais je n’avais aucune idée de comment faire un bon éditeur de texte. Filament m’a fait gagner un temps fou.
Pour booster les performances, j’ai intégré Laravel Octane en production avec FrankenPHP. Contrairement au PHP classique (où chaque requête recrée l’application), Octane garde l’application chargée en mémoire. J’ai choisi FrankenPHP parce que c’est simple à mettre en place et que Server Side Up propose une image Docker bien sécurisée pour la prod.
Autres packages utiles
Laravel Socialite -> pour l’OAuth (Google & GitHub)
Spatie Laravel Permission -> gestion des rôles et permissions
Spatie Laravel Response Cache -> pour le cache (pas encore activé en prod)
Knuckleswtf/Scribe -> pour générer automatiquement la documentation de mon API
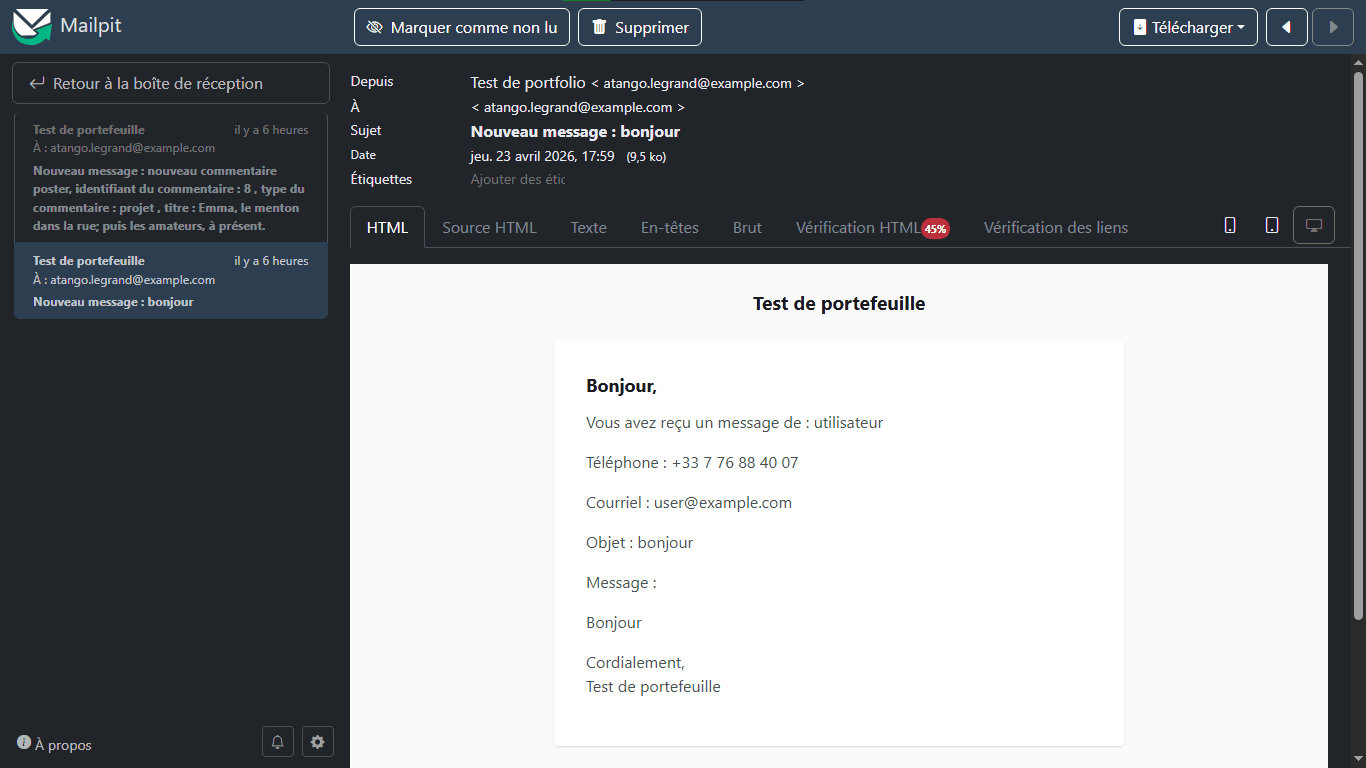
Tu peux d’ailleurs voir à quoi ressemble mon admin Filament avec des données de test ici :
Email : atango.legrand@example.com
Mot de passe : password
Frontend de test : https://front-test.marceldjiofack.com
Interface du serveur SMTP mailpit pour recevoir les couriels : https://mailpit.marceldjiofack.com
B. Frontend
Côté interface, j’ai choisi Nuxt.js (le meta-framework basé sur Vue.js).
Pourquoi Nuxt et pas Vue seul ? Principalement pour le SSR (Server-Side Rendering) et le SEO. Au début, j’envisageais même de faire du SSG (Static Site Generation). J’ai aussi préféré la syntaxe de Vue à celle de JSX/React.
Pour aller vite et avoir une belle cohérence visuelle (sans designer), j’ai utilisé Tailwind CSS + Shadcn-Nuxt (une bibliothèque de composants prêts à l’emploi).
C. Base de données
PostgreSQL est la base de données relationnelle open source la plus avancée au monde, avec une description comme ça pas besoin d’argumenter plus sur son choix mdr… Mais franchement, c’est surtout parce qu’elle est très bien supportée par Laravel et disponible directement dans Laravel Sail.
La vraie raison de mon choix ? PostgreSQL gère très bien le type JSON. J’avais besoin de ça quand j’ai essayé d’ajouter laravel-translatable pour avoir du contenu multilingue (français/anglais). Au final, ça n’a pas marché (ça commence à faire beaucoup d’échecs mdr…), mais j’ai quand même gardé PostgreSQL.
D. Stockage (S3-like)
Au départ, je n’avais pas prévu d’utiliser du stockage objet. Laravel permet de stocker les fichiers directement sur le serveur sans problème.
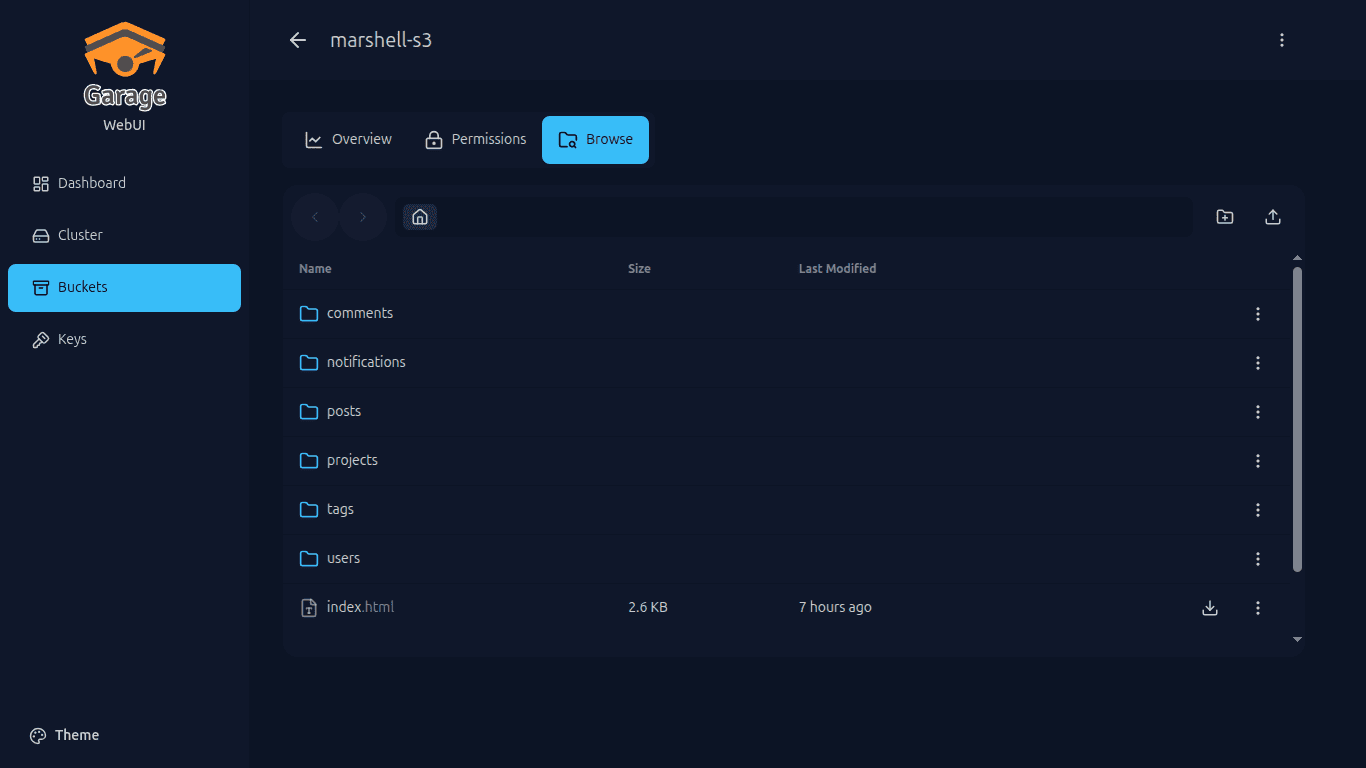
C’est en cherchant un moyen de faire des backups automatiques de la base de données que j’ai commencé à chercher une solution S3 auto-hébergée. Après quelques péripéties, j’ai découvert Garage, un stockage objet open source et distribué, compatible S3.
Il n’y avait presque pas de tutoriels, mais j’ai réussi à le faire fonctionner. Je vous détaillerai les galères dans la section dédiée.
J'aurais aimer vous montrer a quoi ressemble son panneau d'administration avec un lien de test mais malheureusement la webui ne fonctionne que en local au lieu de sa je vais au mois vous montrer a quoi sa ressemble:
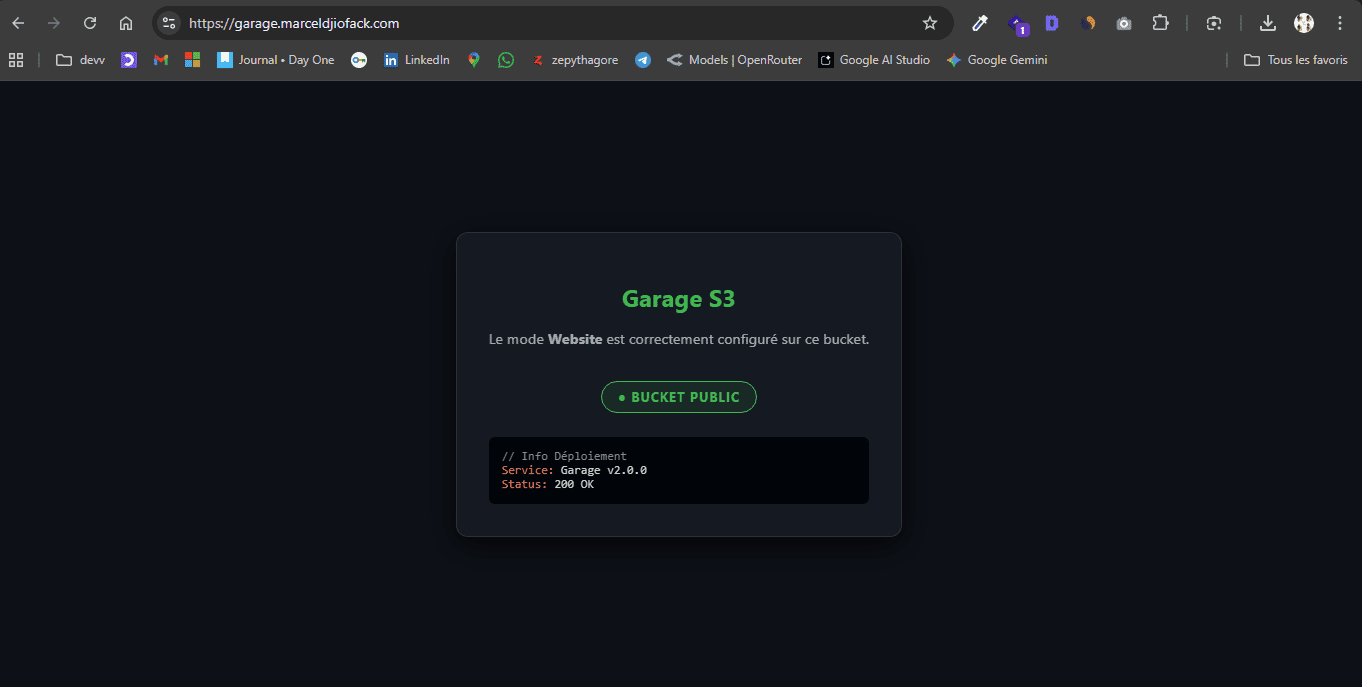
Et garage peut aussi servir de serveur de site statique par exemple si vous allez sur cette url: https://garage.marceldjiofack.com vous pouvez voir cette page html que j'ai mise en ligne juste pour tester, mais bon c'est anecdotique.
E. Redis
Redis, je l’ai installé principalement pour le cache et potentiellement les queues/sessions. Pour l’instant, je l’utilise surtout en local. En production, le cache n’est pas encore activé, donc Redis tourne mais n’est pas vraiment sollicité.
F. Infrastructure & Déploiement
Docker Indispensable. Je l’utilise à la fois en local (via Sail) et en production. C’est selon moi l’un des outils les plus utiles jamais créés pour le développement.
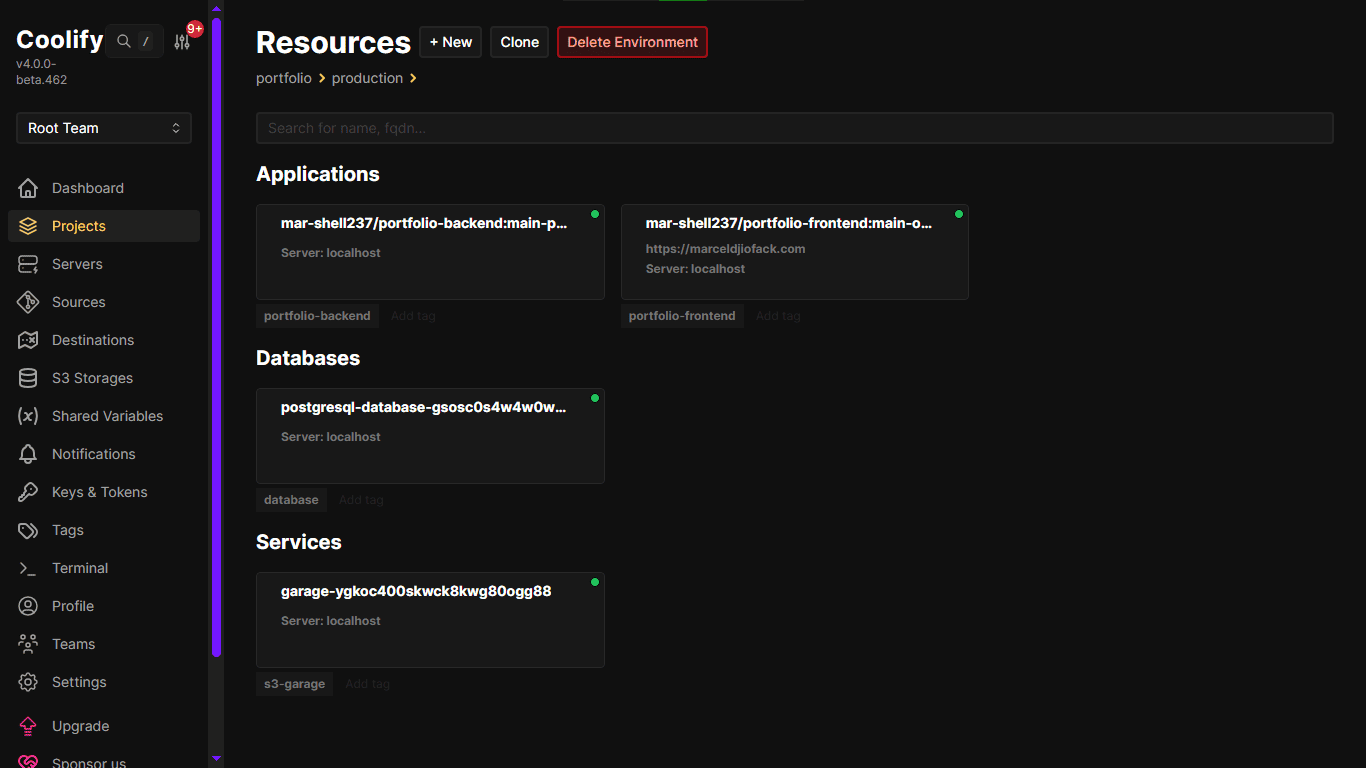
Coolify C’est clairement l’outil qui m’a sauvé la mise. Coolify est une alternative open source à Vercel/Heroku/Netlify/Railway. Tu peux déployer des apps, bases de données, et plus de 280 services en un clic sur ton propre serveur.
Je l’ai choisi parce qu’il est écrit en Laravel (ça m’a fait sourire), qu’il est mature, et qu’il m’a permis d’avoir une interface propre sans devenir un expert sysadmin. Après une commande SSH, tout s’installe, tu as une belle UI, tu connectes ton repo GitHub, et les déploiements se font automatiquement sur push. Franchement, sans Coolify, avec mes moyens limités, j’aurais galéré beaucoup plus.
VPS J’ai pris un VPS chez Contabo. Après comparaison, c’était le meilleur rapport qualité/prix : 8 Go RAM, 4 cœurs, 120 Go SSD pour environ 4 $/mois (descendu à ~3 $ avec l’engagement annuel).
Nom de domaine J’ai acheté marceldjiofack.com chez Cloudflare (11 $). Les sous-domaines (backend, test, storage, etc.) sont gratuits.
III. LE PARCOURS & GALERES
Le développement a duré environ 6 mois, de fin octobre 2025 à mi-avril 2026. Ça peut sembler long pour « juste » un portfolio, mais ce fut tout sauf linéaire. Il y a eu des phases où j’avançais très vite et d’autres où j’étais complètement bloqué, avec des moments de gros doute.
Dès le départ, j’ai attaqué le backend par les bases : création des routes API les plus évidentes, modèles, migrations, seeders et factories. Ça a été plutôt rapide, je dirais à peine deux semaines. Grâce à mon expérience avec Laravel, cette partie était confortable pour moi.
J’ai aussi pris le temps sur des fonctionnalités plus délicates qui faisaient partie de mes objectifs : l’authentification par session avec cookies HTTP-only (c’était ma première vraie tentative), la vérification d’email à l’inscription, le mot de passe oublié, et surtout le système de commentaires avec réponses à profondeur infinie. Il fallait aussi ajouter les seeders et factories pour pouvoir tester facilement.
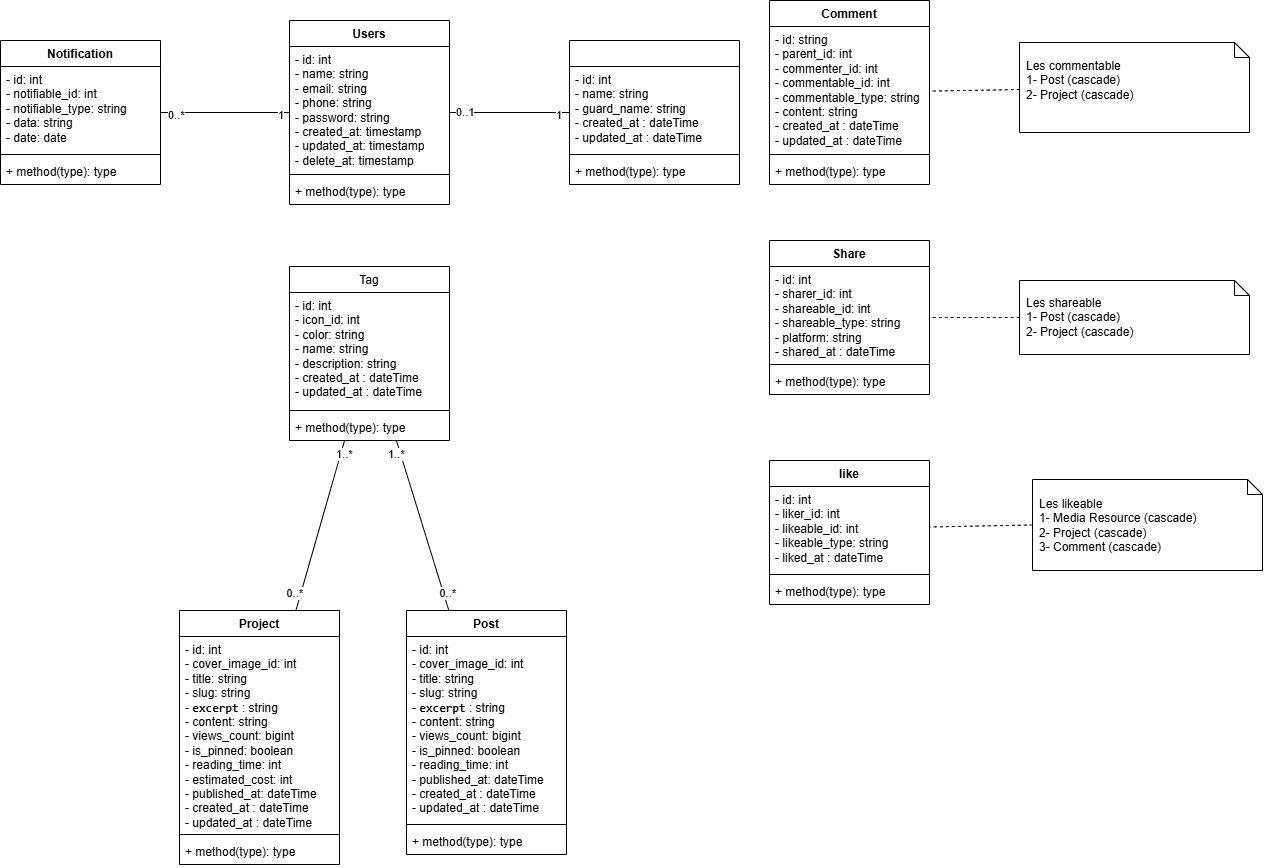
Avant même de commencer à coder, je n’avais fait qu’un petit diagramme de classes pour représenter le schéma de base de données. Pas de cahier des charges, pas de wireframes, rien. Je ne savais pas précisément tout ce que je voulais, donc j’avais décidé d’y aller au feeling au fur et à mesure que le développement avançait.
Après cette première phase backend, il a fallu que je me remette sérieusement au frontend… et là, ça a été un vrai retour en arrière.
En tant que bon autodidacte, j’avais commencé par apprendre le frontend (HTML, CSS, puis Vue.js) pendant mes premières années à l’université. À l’époque, le code que tu écrivais s’affichait directement dans le navigateur, c’était concret et immédiat. Après ça, j’ai directement appris Vue.js sans vraiment maîtriser JavaScript en profondeur. J’avais choisi Vue parce qu’on m’avait dit que c’était plus simple que React, et aujourd’hui je confirme totalement cet avis.
Mais après l’épisode de ma première page de contact qui était inutilisable (parce que je ne savais rien faire en backend), j’avais dû me tourner vers Laravel. On l’avait utilisé pour un TP en programmation web et ça m’avait plu. Pendant presque un an, à chaque projet académique, j’étais dans l’équipe backend. Résultat : pendant tout ce temps, je n’ai plus écrit une seule ligne de HTML.
Du coup, quand est venu le moment de coder l’interface de ce portfolio, j’ai dû prendre quelques jours pour relire la documentation de Nuxt.js, me remémorer la syntaxe de Vue.js, et chercher les outils qui pouvaient m’aider (notamment une bonne bibliothèque de composants). C’était un peu étrange de revenir à ce que j’aimais au début, mais avec un an de pause.
Une fois que le backend communiquait correctement avec le frontend et que j’avais des données de test, je suis passé à l’administration. Filament est arrivé à ce moment-là et m’a grandement simplifié la vie. Il suffisait de lire la doc et d’adapter ce qu’il fallait. Rien d’extraordinaire, mais très efficace.
Et c’est comme ça que, de fin octobre jusqu’au 24 janvier 2026, j’ai fait des aller-retours constants entre le backend et le frontend : j’ajoutais une fonctionnalité d’un côté, je l’affichais de l’autre, je corrigeais, etc. La dernière grosse partie que je me souviens avoir terminée à cette période, c’était l’affichage des commentaires et des sous-commentaires à l’infini, avec tout ce que ça implique (liker, répondre, etc.). Un vaste chantier.
Le 25 janvier 2026, grâce à une bourse d’excellence académique que j’ai reçue de la part du chef de l’État, j’ai enfin pu payer mon VPS chez Contabo pour un an et mon nom de domaine. J’avais déjà testé Coolify pendant un mois, les tests étaient concluants. Le même jour, j’ai créé et connecté la base de données, hébergé le backend, le frontend, connecté le domaine… et j’ai même envoyé le lien à certaines de mes connaissances pour qu’ils voient le fruit de mon travail.
Sauf que… nous n’étions qu’en fin janvier. Il restait encore trois mois de développement. Pourquoi ?
Parce que tout ne fonctionnait pas du tout parfaitement en production.
Le plus gros cauchemar a commencé avec le système de files d’attente (queues). C’est primordial, car c’est ce qui me permet d’envoyer les emails de confirmation ou de réinitialisation de mot de passe. Dans Laravel, il faut lancer une commande pour traiter les jobs. Coolify propose une section pour exécuter des commandes après chaque déploiement réussi, donc je me suis dit « jackpot ». J’ai renseigné la commande… et là, surprise : soit ça ne fonctionnait pas, soit le serveur s’arrêtait juste après.
J’ai cherché partout, mais il n’y avait presque aucun tutoriel clair. La doc de Laravel parlait d’installer Supervisor sur Linux… mais je n’y comprenais rien et j’avais une peur bleue de me connecter en SSH au serveur et de tout casser (je ne m’étais connecté qu’une seule fois avant, juste pour installer Coolify). La solution proposée par Coolify avec le fichier unit.json était obsolète. J’ai donc été obligé d’apprendre Docker en profondeur : images, containers, volumes, réseaux, Docker Compose… des concepts que je n’utilisais avant que via Laravel Sail sans vraiment comprendre.
Après plusieurs semaines de recherches désespérées, d’articles lus en boucle et de tests à tâtons, j’ai fini par tomber sur Server Side Up grâce à un commentaire sur Reddit (dans le subreddit selfhosting). Leurs images Docker ultra-documentées m’ont sauvé. La solution était finalement assez simple : dupliquer le service dans le docker-compose.yml et lancer la commande des queues sur un second container dédié. Le jour où j’ai enfin réussi, c’était un immense soulagement. Presque un mois et demi à fouiller le net pour un seul problème.
Après ça, j’ai eu quelques soucis mineurs avec Coolify, mais rien de comparable.
Pendant toute cette période, j’ai aussi subi des coupures d’électricité pendant presque 3 semaines à cause de chutes de poteaux. Je ne pouvais rien faire d’autre que me reposer et attendre… ce qui n’a pas aidé pour le moral.
L’autre grosse galère a été la mise en place de Garage (mon S3 auto-hébergé). J’en parlerai plus en détail dans un futur article, mais en gros : j’ai d’abord essayé MinIO qui avait abandonné l’open source, puis je suis passé sur Garage. Aucun tutoriel, pas d’interface graphique native, tout en CLI. En local ça a fini par marcher avec une WebUI open source, mais en production sur Coolify ça a été une autre histoire. La WebUI refusait de se connecter correctement à l’instance. J’ai tâtonné pendant des jours sur les variables d’environnement, les réseaux Docker, etc. Finalement, j’ai dû configurer la WebUI en local pour qu’elle se connecte à l’instance de production. Ça a fonctionné, mais jusqu’à aujourd’hui je ne sais toujours pas pourquoi ça ne marche pas directement sur le serveur (si quelqu'un sait pourquoi sa ne marche pas je suis preneur).
En résumé, entre les commentaires imbriqués à l’infini, les files d’attente en production, la configuration de Garage, les coupures d’électricité et mes moments de gros doute, il y avait largement de quoi abandonner comme je l’avais fait sur tous mes projets précédents, cette fois ci tout fonctionne et en production !
Mais cette fois, je m’étais fait une promesse claire : je ne toucherais à rien d’autre tant que ce portfolio ne serait pas fini et en ligne avec un vrai nom de domaine. Même quand le moral était au plus bas, après une bonne nuit de sommeil, je revenais toujours à la charge. Et c’est grâce à cette restriction que j’ai réussi à aller jusqu’au bout.
Si jamais tu veux que j’écrive un article détaillé sur comment héberger Laravel avec queues sur Coolify, ou comment faire fonctionner Garage + Laravel en production, n’hésite surtout pas à me le dire en commentaire. Je le ferai avec plaisir.
IV. LES PISTES ABANDONNEES
Au début du projet, j’avais de grandes ambitions. Des ambitions qui semblaient théoriquement faciles à réaliser… mais comme on dit souvent, l’informatique n’est pas une science exacte. Mdr. La théorie est souvent très éloignée de la pratique, et j’en ai eu la preuve plusieurs fois.
A. Le site statique (SSG)
Dès le départ, je voulais utiliser la fonctionnalité SSG (Static Site Generation) de Nuxt.js pour maximiser les performances.
Le principe est simple : tu tapes une commande, Nuxt fait tous les appels au backend pour récupérer les données nécessaires, et il génère des fichiers HTML statiques. Résultat : quand un utilisateur demande une page (un article par exemple), c’est instantané. Pas d’appel au backend, pas d’attente que le JavaScript s’exécute. Théoriquement, c’était parfait pour la performance et le SEO.
Mais pourquoi j’ai abandonné ?
D’abord à cause du multilingue (que je vais détailler juste après). J’avais installé nuxt-i18n, mais j’ai rencontré d’énormes problèmes : dans le dossier de sortie, j’avais bien deux dossiers en et fr, sauf que le dossier en contenait exactement les mêmes fichiers que le dossier fr, avec le même contenu en français. J’ai tout essayé, ça n’a jamais fonctionné correctement.
Même après avoir abandonné le multilingue, le vrai problème est apparu en production. En local, il suffit de taper une commande pour régénérer tout le site. Mais en production, ça voulait dire que à chaque nouvel article ou à chaque petite modification, je devais redéployer entièrement le frontend pour régénérer toutes les pages. C’était fastidieux et probablement coûteux en ressources, car chaque déploiement régénérait tout le site.
J’avais bien une piste pour automatiser ça (utiliser un webhook depuis le backend pour signaler a coolify de redeployer le site), mais ça me semblait beaucoup trop complexe pour pas grand-chose. À ce moment-là, j’avais déjà réalisé que le mode SSR classique de Nuxt remplissait très bien mes besoins en termes de SEO et de performance.
C’est là que j’ai compris le piège de la JAMSTACK : au début je me demandais pourquoi je n’entendais presque jamais parler de cette technique. Maintenant je sais pourquoi. Le SSG pur est selon moi parfait pour des sites vraiment statiques, sans backend, où le développeur ne veut pas écrire du HTML brut. Personnellement, je ne ferai plus jamais de site avec du simple HTML statique. Par contre, je trouve que le SSG peut être utilisé intelligemment de manière partielle (par exemple pour la page « À propos » ou les pages de login/contact qui n’ont besoin d’appeler le backend que pour soumettre des données).
B. Le multilingue
Comme vous le savez peut-être, je suis camerounais et très fier de l’être. Je voulais absolument que mon portfolio soit disponible en anglais, pour refléter le fait que le Cameroun est un pays bilingue.
Côté frontend, j’avais installé nuxt-i18n pour les textes statiques (titres, menus, etc.). Mais je voulais d’abord m’assurer que les contenus dynamiques (ceux qui viennent du backend) soient aussi multilingues. Quand je faisais une requête, je devais pouvoir préciser la langue voulue (par défaut : français).
Côté backend, j’ai utilisé le package laravel-translatable de Spatie. Et ça marchait ! Quand je demandais les données en anglais, je recevais bien le contenu traduit.
Alors pourquoi j’ai abandonné ?
D’abord, les problèmes avec le SSG ont déjà bien entamé mon enthousiasme. Mais même après avoir laissé tomber le SSG, un obstacle majeur est apparu : Filament (l’outil qui m’a fait gagner un temps fou sur le dashboard) n’est pas du tout pensé pour le multilingue. Pour stocker des champs dans plusieurs langues, il faut utiliser du JSON dans la base de données. Sauf que Filament pète un câble avec les champs JSON. Il existe bien des plugins, mais ils ne sont pas à jour, et j’ai tout essayé sans réussir à le faire fonctionner correctement.
En plus, pendant les périodes de coupures d’électricité, je me suis posé la question honnêtement : est-ce que j’avais vraiment besoin du multilingue maintenant ? Le Cameroun est bilingue, oui, mais moi je ne suis pas parfaitement bilingue. Traduire tout cet article en anglais par exemple me demanderait beaucoup de travail (outils de traduction + relecture manuelle). Je n’étais pas sûr de pouvoir assumer cette charge correctement.
Du coup, j’ai décidé de reporter le multilingue à plus tard. Ce n’est pas vraiment un abandon définitif. Un jour, je reviendrai dessus : je pourrai recoder mon propre dashboard (sans Filament) pour avoir le contrôle total, et j’ai vu que Coolify permet d’installer LibreTranslate (une API de traduction automatique open source et auto-hébergée) en un clic. Ça pourrait m’aider à traduire automatiquement les textes.
En résumé, le multilingue est plutôt reporté que vraiment abandonné. Après six mois de travail, je voulais simplement finir le projet et le mettre en ligne.
C. Le cache
Celui-là, ce n’est ni un abandon ni un report. J’ai tout mis en place pour qu’il fonctionne, mais je l’ai désactivé pour des raisons de simplicité.
Côté backend, j’ai installé spatie/laravel-responsecache. Il sauvegarde le résultat des réponses JSON des routes GET (dans PostgreSQL ou Redis) lors de la première requête. Ensuite, les requêtes suivantes renvoient directement la réponse en cache, sans re-exécuter tout le code ni interroger la base de données.
Côté frontend, je voulais installer TanStack Query pour garder les données en cache côté client, mais j’ai lu que Nuxt.js le faisait déjà assez bien avec son système de fetch et de stores. Du coup, je ne l’ai même pas installé.
Pourquoi je l’ai désactivé alors que tout était prêt ?
D’abord pour la simplicité. Mais surtout parce que la gestion du cache n’était pas encore comme je voulais : à chaque modification (même mineure), je devais purger tout le cache, même les données qui n’étaient pas concernées. C’était lourd et pas très élégant. Comme ce n’était pas urgent et que je voulais sortir le projet, j’ai préféré désactiver le cache pour l’instant.
Je ne le considère ni comme abandonné ni comme reporté. C’est juste inutile pour le moment. Je pourrai le réactiver plus tard et mettre en place une purge plus fine. D’ailleurs, je l’ai quand même implémenté au départ parce que ce projet était aussi un laboratoire pour apprendre de nouvelles choses.
Conclusion
C’est ici que s’achève le récit de ces six mois de travail acharné.
Ce projet, qui ne devait être qu’un « simple » portfolio, s’est transformé en une véritable école de la persévérance. J’ai appris qu’entre le code qui tourne en local et une application robuste en production, il y a un monde de configurations, de bugs imprévus et de nuits blanches. Mais aujourd’hui, voir marceldjiofack.com en ligne, propulsé par mon propre serveur, est une satisfaction que je ne regrette pour rien au monde.
Un petit mot pour finir : comme c'est le tout premier article que je rédige (et j'y ai passé presque trois jours !), je sollicite votre indulgence. Je sais que le chemin est encore long, tant en écriture qu'en développement.
D'ailleurs, j'aimerais beaucoup avoir votre avis honnête :
Est-ce que ce format de "devlog" est trop long à votre goût ?
Avez-vous eu l'impression que je me suis trop répété ?
Si vous avez des conseils, que ce soit sur l'écriture, mes choix d'architecture ou même sur mes galères avec Docker et Garage, je suis preneur !
Merci de m'avoir lu jusqu'au bout. Ce n'est que le début de l'aventure , et j'ai déjà hâte de vous partager les prochaines étapes.